Ya disponible la versión Beta de Assets Data Manager
 Atlassian ha anunciado la disponibilidad de la versión Beta de Assets Data Manager, una herramienta clave para la gestión de activos empresariales. Este lanzamiento es un paso importante tras la adquisición de AirTrack en 2023, con la que Atlassian fortaleció su oferta en la gestión de activos y configuraciones, consolidando su solución bajo la nueva marca Assets Data Manager.
Atlassian ha anunciado la disponibilidad de la versión Beta de Assets Data Manager, una herramienta clave para la gestión de activos empresariales. Este lanzamiento es un paso importante tras la adquisición de AirTrack en 2023, con la que Atlassian fortaleció su oferta en la gestión de activos y configuraciones, consolidando su solución bajo la nueva marca Assets Data Manager.
La herramienta permite a las organizaciones importar activos de manera eficiente, ya sea mediante archivos CSV o a través de adaptadores que integran sistemas de gestión de activos existentes en la empresa.
Además, Assets Data Manager facilita la normalización de datos, la creación de filtros personalizados y la generación de informes detallados. Estas capacidades mejoran la visibilidad de los equipos y optimizan la toma de decisiones estratégicas, al ofrecer una vista centralizada y clara del ecosistema de activos de la organización.
Este lanzamiento refuerza el compromiso de Atlassian con la innovación en la gestión de TI y servicios empresariales. ¡La versión Beta ya está disponible para quienes deseen explorar su potencial!
¿Cómo habilitar el Data Manager?
Iremos a la sección de Assets en el menú de Configuración para poder habilitarlo.
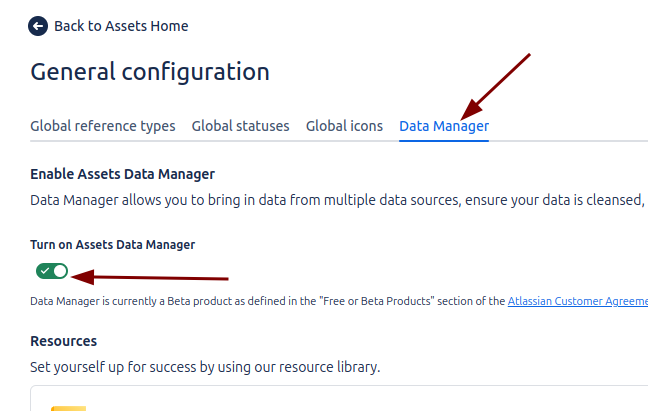
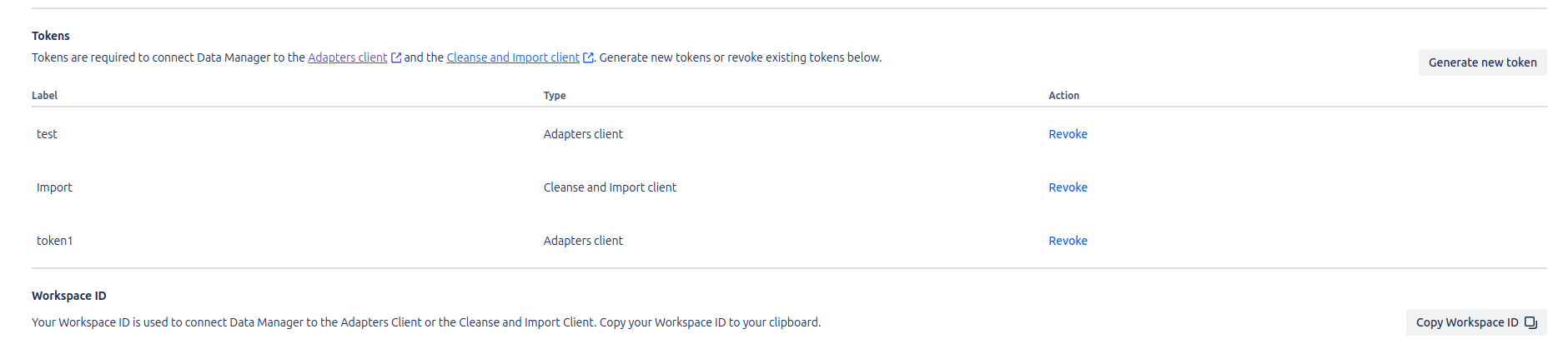
En el menú de configuración de Assets Data Manager, es posible gestionar los roles de acceso, generar tokens temporales (con una validez máxima de 12 meses) para la ejecución de tareas, y consultar el Workspace ID, necesario para llevar a cabo acciones como Jobs o Cleanse & Import.
Una vez activado Data Manager, los usuarios podrán acceder al panel principal de Assets y configurar la herramienta según las necesidades de su organización. Esto proporciona un control centralizado y flexible para la gestión de activos y flujos de trabajo.
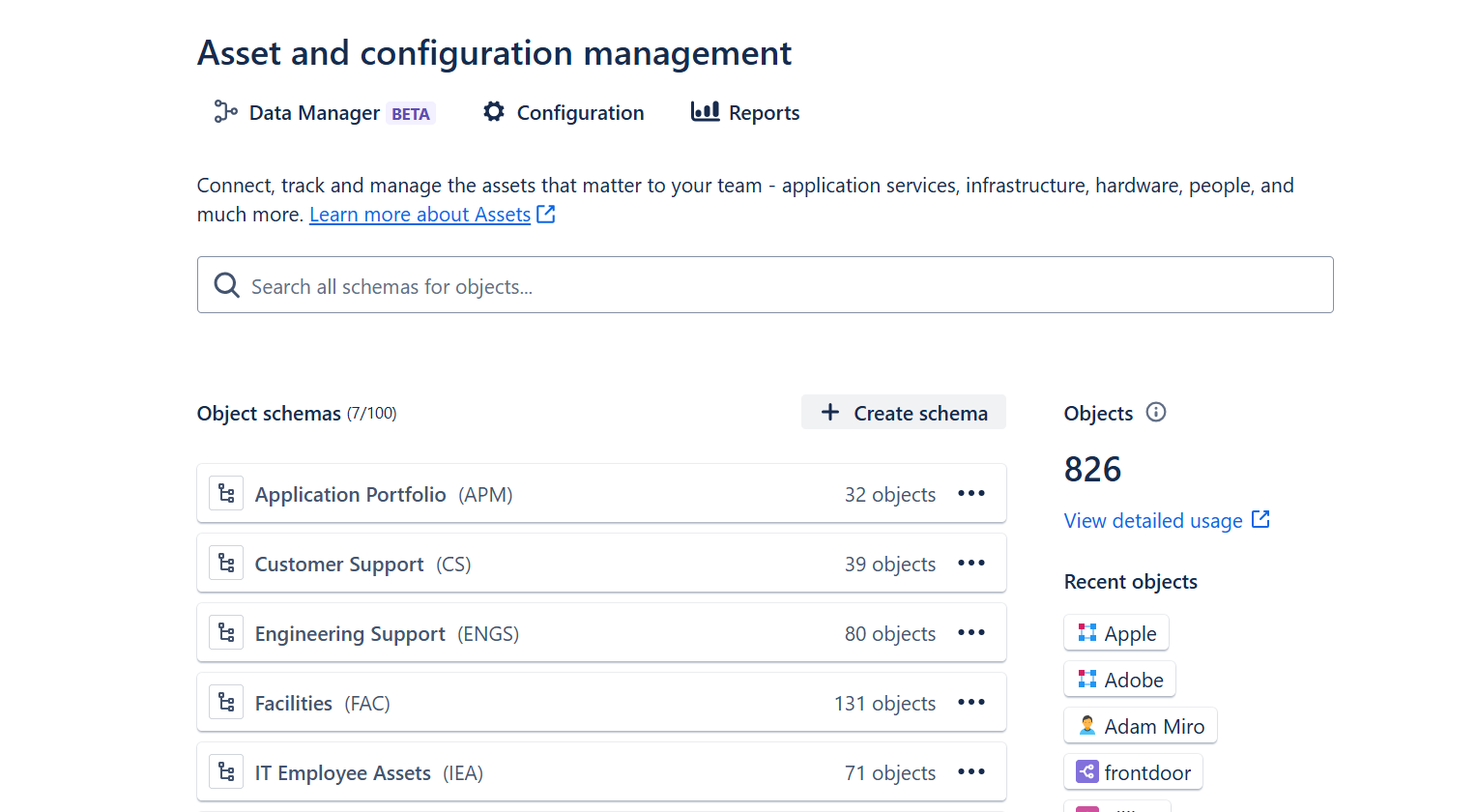
Empezar a configurar Data Manager
Cómo crear Jobs en adaptadores
El primer paso para integrar Assets Data Manager es preparar el servicio con el que deseamos establecer la conexión, como Azure, Lansweeper o ServiceNow. Cada uno de estos servicios cuenta con especificaciones únicas que deben ser consideradas durante la configuración.
Para garantizar una integración exitosa, es posible consultar las instrucciones específicas para cada servicio directamente desde el apartado correspondiente en la herramienta. Este enfoque asegura que la configuración sea precisa y adecuada a las características de cada entorno, lo podemos consultar de forma más concreta desde este apartado.
Una vez configurado el servicio en el paso anterior, el siguiente paso es crear un Job en Assets Data Manager. Este Job será responsable de importar los datos desde la herramienta previamente conectada, asegurando que la información se integre de manera eficiente en la plataforma.
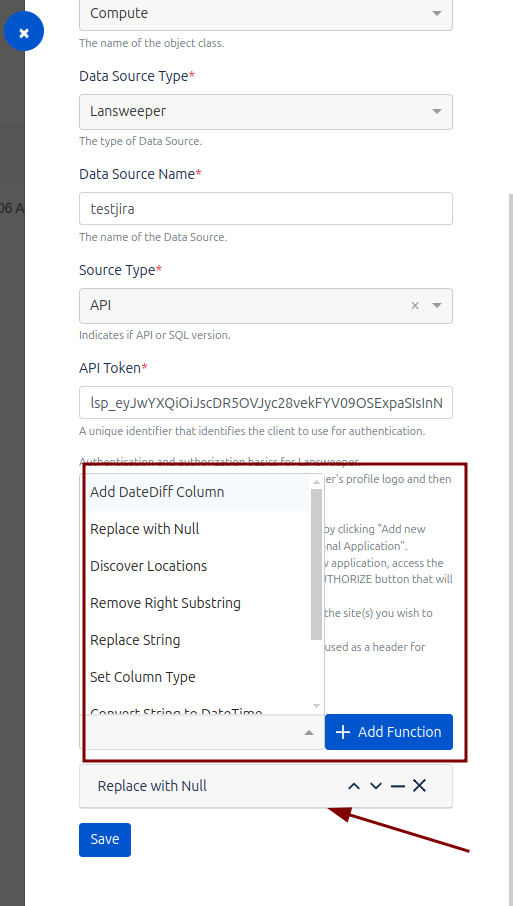
Dentro de la configuración del Job en Assets Data Manager, es posible definir reglas de transformación. Estas reglas se ejecutarán automáticamente al recopilar la información traída por el Job, permitiendo modificar o dar formato a los datos antes de que sean importados y almacenados en el sistema. Esta funcionalidad asegura que la información se ajuste a los estándares y requisitos específicos de la organización, optimizando la calidad y consistencia de los datos importados.
En la sección All Jobs de Assets Data Manager, podremos visualizar los Jobs que ya han sido habilitados y configurados. Esta área centraliza todos los trabajos activos, permitiendo monitorear su estado y asegurarse de que la importación y procesamiento de datos se esté llevando a cabo correctamente.
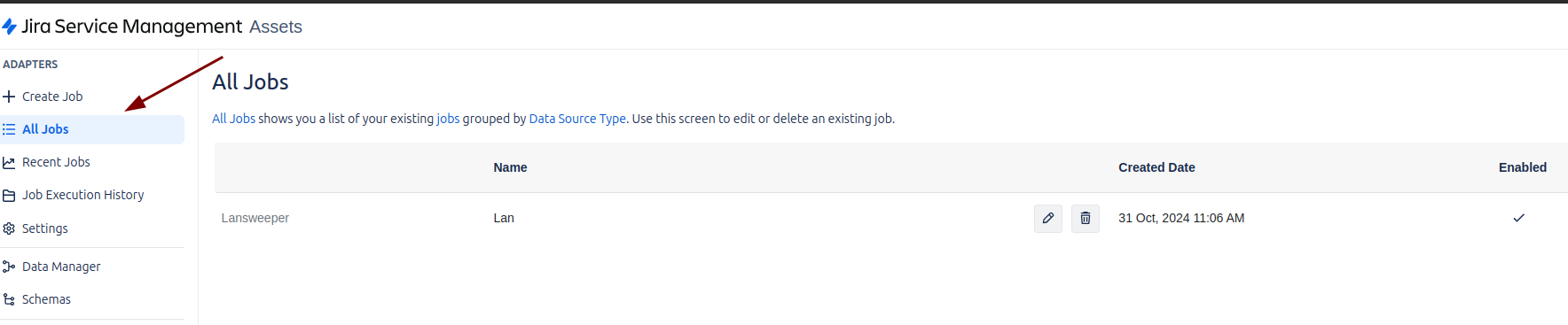
Cómo ejecutar un Job
Para ejecutar el Job en Assets Data Manager, es necesario descargar el cliente de Data Manager desde el Atlassian Marketplace. Este cliente facilita la conexión y ejecución de tareas relacionadas con los activos.
Una vez descargado el cliente, deberás obtener el Token y el Organization ID desde el apartado de Assets en la configuración de Jira. Estos datos son esenciales para autenticar y configurar correctamente la ejecución de los Jobs dentro del entorno de Assets Data Manager.
Una vez descargado e instalado el cliente de Data Manager en Windows, podrás utilizar el comando dm-adapters.exe para interactuar con Assets Data Manager desde la línea de comandos. Para obtener ayuda sobre los comandos disponibles, simplemente abre una ventana de Símbolo del sistema (Command Prompt) y ejecuta el siguiente comando: dm-adapters.exe –help
Este comando proporcionará una lista de opciones y parámetros que puedes usar para ejecutar y configurar diferentes tareas relacionadas con los adapters de Assets Data Manager, como la ejecución de Jobs, la configuración de la conexión y la importación de datos.

Para automatizar la ejecución de un Job en Assets Data Manager mediante un schedule, puedes programar el comando anterior utilizando el Programador de Tareas de Windows (Task Scheduler). Esto te permitirá ejecutar el Job de manera periódica, sin necesidad de intervención manual.
Cómo ver que datos ha traído el Job
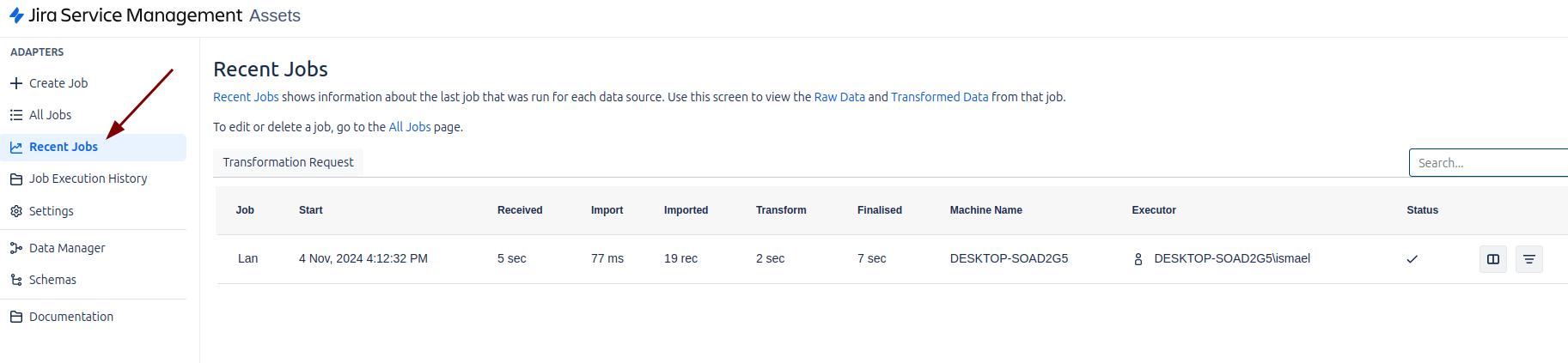
Para ver el estado de los trabajos ejecutados, debemos acceder al menú izquierdo y seleccionar la opción “Recent Jobs”. Esta sección nos permitirá revisar los detalles de los trabajos que se han ejecutado recientemente, incluyendo su estado, duración, y cualquier error o advertencia que haya podido ocurrir durante su ejecución.
En “Recent Jobs”, podrás:
- Consultar los resultados de los Jobs programados o manuales.
- Visualizar los registros de ejecución para cada Job.
- Identificar problemas o verificar que los trabajos se hayan completado correctamente.
Es una herramienta muy útil para monitorear y gestionar los Jobs de manera eficiente.
Tratar datos en Data Manager
Una vez que el Job se ha ejecutado correctamente sin errores, el siguiente paso es procesar y normalizar los datos importados. Esto incluye la definición de reglas de limpieza, el mapeo de los campos importados y la ejecución de la limpieza para asegurar que los datos estén alineados con los estándares de la organización.
Para comenzar con la normalización y limpieza de los datos en Assets Data Manager, el primer paso es ir a la sección de configuración (Settings).
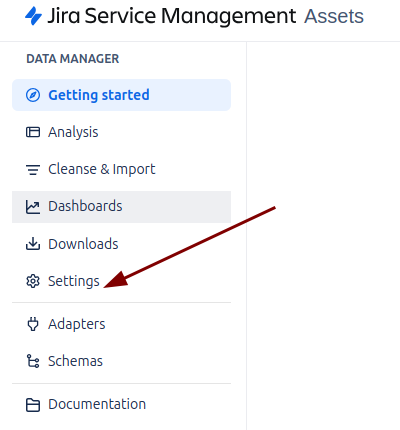
En esta sección nos encontraremos los siguientes apartados para configurar:
Data Source Types
En esta sección se encuentran los tipos de fuentes de datos (data sources) que has configurado previamente en el apartado de Jobs. Por defecto, ya se incluyen algunos ejemplos, pero a medida que vayas creando y ejecutando Jobs, los Data Source Types se irán agregando automáticamente según las fuentes configuradas. Esto permite tener un control sobre las distintas fuentes de datos que se manejan dentro del sistema.
Data Sources
En esta pestaña es donde llevarás a cabo las tareas clave de mapeo, limpieza e importación de datos a Data Manager. Aquí podrás ajustar cómo los datos importados se asignan a los campos correctos dentro de la plataforma, definir reglas de limpieza para eliminar datos erróneos o duplicados, y finalmente importar los datos ya normalizados y validados al sistema.
Computed Dictionary
Este apartado te permite definir campos computados basados en atributos existentes. Por ejemplo, puedes crear un campo «OSVersion» que agrupe los valores de sistema operativo, como «Linux» o «Windows», y dentro de cada clase, listar las versiones correspondientes (por ejemplo, «Ubuntu», «Debian» para Linux, o «Windows 10», «Windows 11» para Windows). Dependiendo de los valores de los atributos, el sistema asignará automáticamente el valor «Linux» o «Windows» a la columna correspondiente.
Computed Issues
En esta sección podrás asociar más fácilmente los valores a los grupos dentro del «Computed Dictionary». Esto facilita la organización y asignación de valores dentro de los campos computados, permitiendo una configuración más estructurada y eficiente de los datos.
Reasons
Aquí podrás crear diferentes razones de limpieza para aplicar antes de importar los datos. Al realizar un proceso de limpieza (cleanse), podrás marcar los datos con una razón específica que explique por qué esos datos fueron modificados o eliminados. Esto ayuda a mantener un registro claro de las modificaciones realizadas a los datos importados y facilita la auditoría y el control de calidad.
Attributes
Los atributos son los campos de las tablas que definen las características de cada object class. Cada clase de objeto puede tener atributos que representen propiedades específicas (como nombre, fecha de creación, estado, etc.). Los atributos pueden ser:
- Normales: Son los atributos que no requieren ningún procesamiento adicional.
- Computados: Son aquellos que se calculan utilizando reglas definidas en el Computed Dictionary.
Algunos atributos pueden estar marcados con snapshot, lo que significa que los valores de esos atributos se almacenarán como una instantánea en un punto del tiempo, permitiendo realizar comparaciones entre los valores históricos y futuros.
Attribute Priorities
Aunque no se encuentra especificado en el documento, esta sección suele gestionar la prioridad de los atributos cuando hay conflictos o se deben aplicar reglas de transformación. Los atributos con una mayor prioridad pueden sobrescribir los valores de los atributos con menor prioridad durante el proceso de importación.
Default Attribute Mapping
Aquí se definen las columnas por defecto que se mapearán desde la fuente de datos al object class correspondiente. Este mapeo predeterminado asegura que los datos importados se asignen correctamente a los campos establecidos, sin necesidad de configuraciones adicionales para cada importación.
Default Cleansing Rules
En esta sección se definen las reglas de limpieza predeterminadas que se aplicarán automáticamente a todos los datos importados. Estas reglas pueden incluir la eliminación de valores vacíos, la corrección de formatos, o la validación de datos. Si es necesario, estas reglas se pueden personalizar para cada Job específico, proporcionando flexibilidad en la gestión de los datos.
Cleanse & Import
En Assets Data Manager, la limpieza, el mapeo y la importación de los datos traídos desde el data source se pueden gestionar a través de una interfaz web.
Cada vez que se crea un Job, se genera un registro correspondiente en esta sección.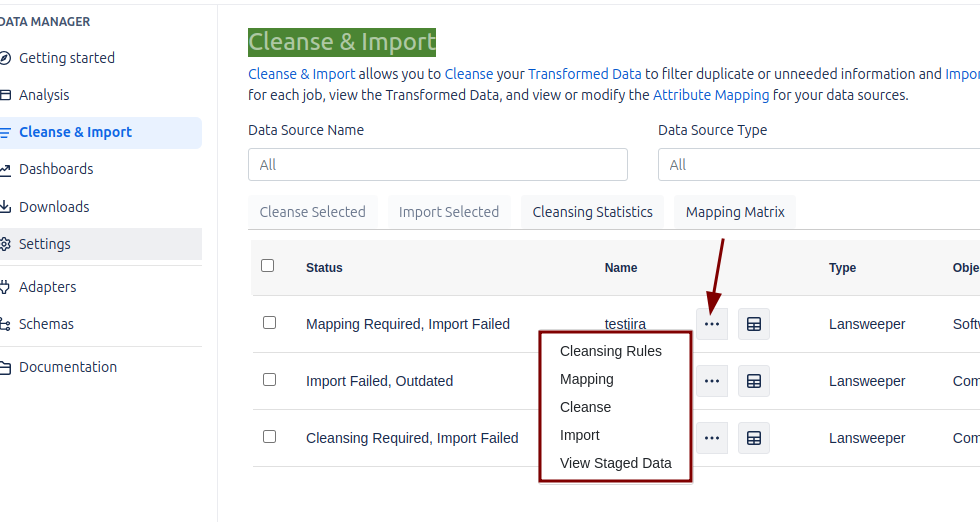
Además de la ejecución manual a través de la interfaz web, Cleanse e Import también pueden ser programados para ejecutarse automáticamente en intervalos específicos, utilizando el cliente de Data Manager junto con el Programador de Tareas de Windows. Esta es la única forma de programar estas tareas de forma automatizada.
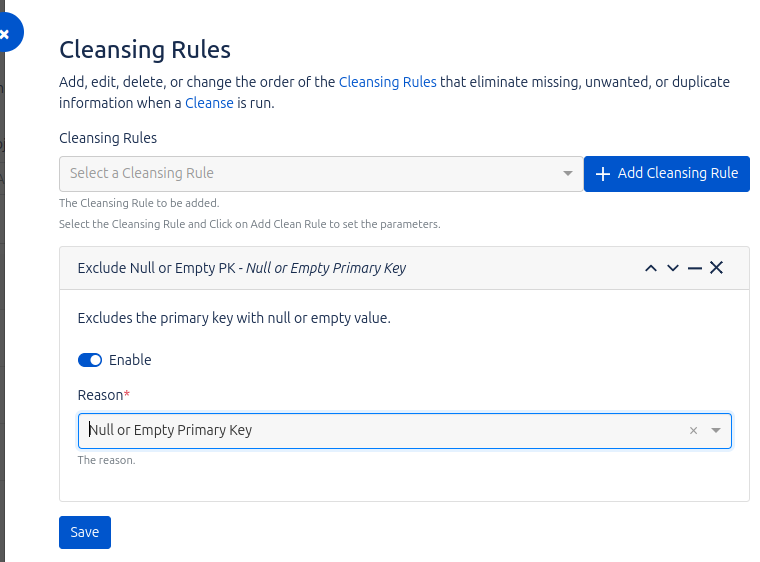
Cleansing Rules
En esta sección, podemos configurar las reglas de limpieza que consideremos necesarias para optimizar la calidad de los datos antes de su importación en Assets Data Manager. El producto incluye un conjunto de reglas predefinidas que pueden ser adaptadas a nuestras necesidades mediante las opciones que nos ofrece el sistema.
Por ejemplo, una de las reglas predefinidas es «Exclude null or empty primary keys». Al aplicar esta regla, el proceso de limpieza evitará que las filas con valores nulos en la columna definida como primary key durante el mapeo sean copiadas a Data Manager. De este modo, se asegura que solo los registros completos y válidos sean importados.
Además, es importante destacar que cada Job puede tener sus propias reglas de limpieza personalizadas, lo que permite una mayor flexibilidad en la configuración de los procesos de importación y asegura que se cumplan los requisitos específicos de cada proyecto.
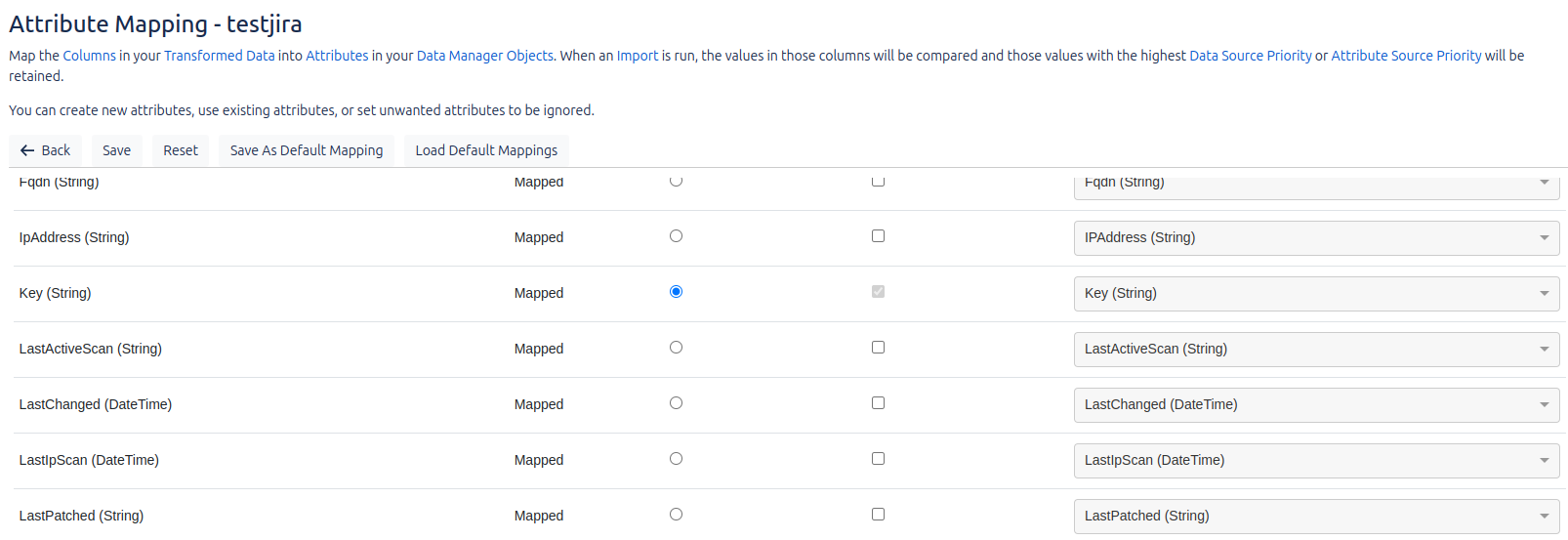
Mapping
El mapeo de campos se refiere a la correspondencia entre los campos provenientes de las fuentes de datos y los campos en Data Manager. En esta sección, definimos cómo deben ser renombrados o asignados los datos importados para asegurar que se ajusten a la estructura y nomenclatura de Data Manager.
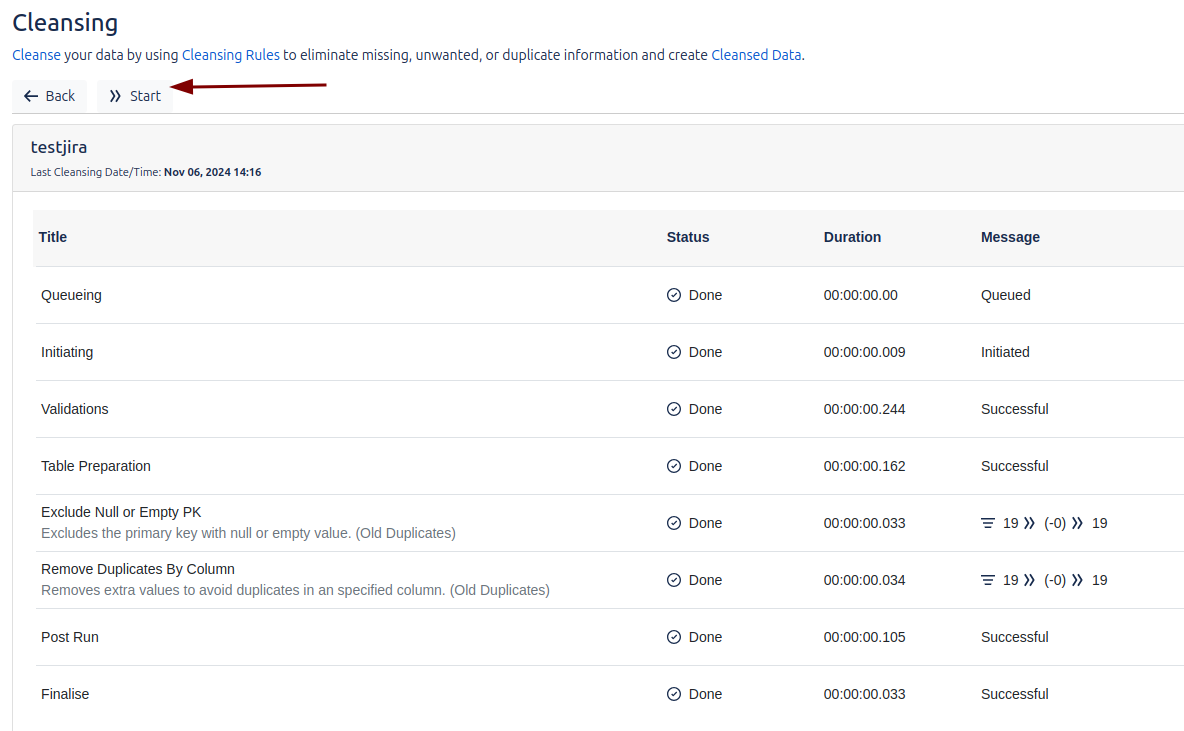
Cleansing
Podemos ejecutar el trabajo de manera manual en cualquier momento. Además, durante la ejecución, podemos monitorear el estado del proceso en tiempo real.
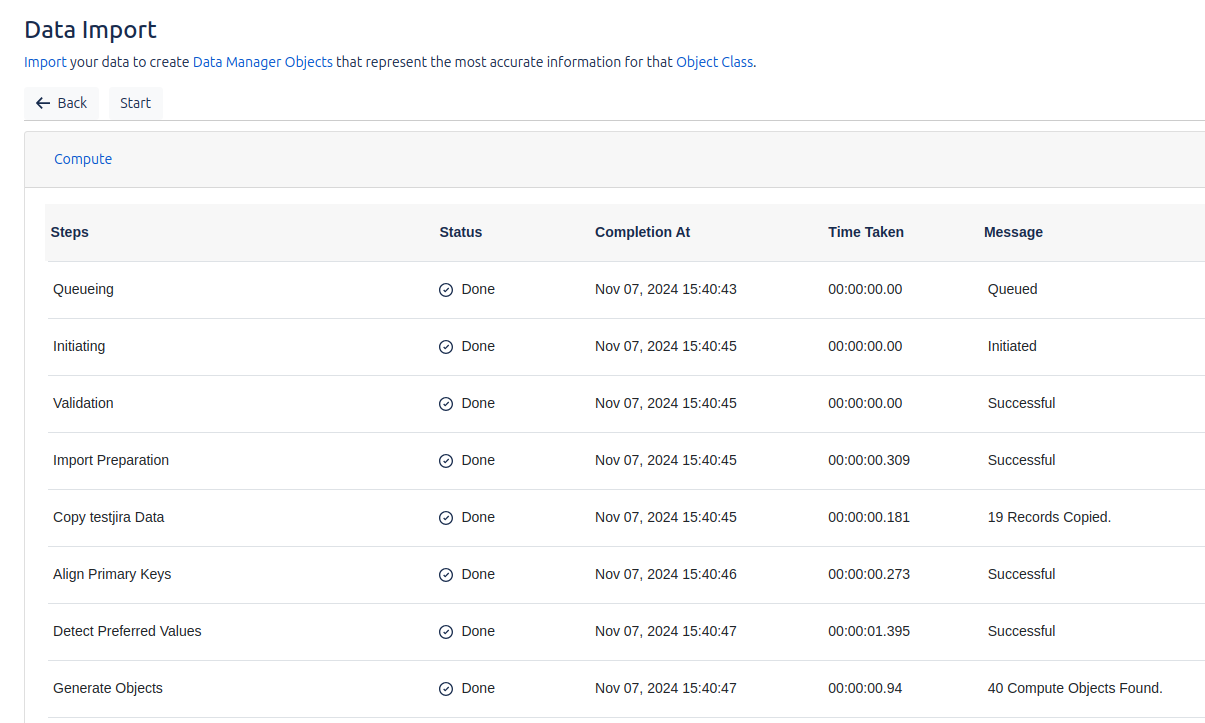
Import
Podremos ejecutar el trabajo de manera manual en cualquier momento, y también tendremos la posibilidad de ver el estado del proceso en tiempo real. Es importante destacar que la ejecución del proceso de limpieza (cleansing) es obligatoria antes de realizar cualquier otra operación. Si intentamos ejecutar el trabajo sin haber realizado previamente la limpieza, se generará un error, lo que resalta la importancia de seguir el flujo de trabajo correcto para asegurar una importación exitosa y libre de problemas.
Una vez que se haya ejecutado el proceso de limpieza, podremos visualizar los resultados obtenidos.
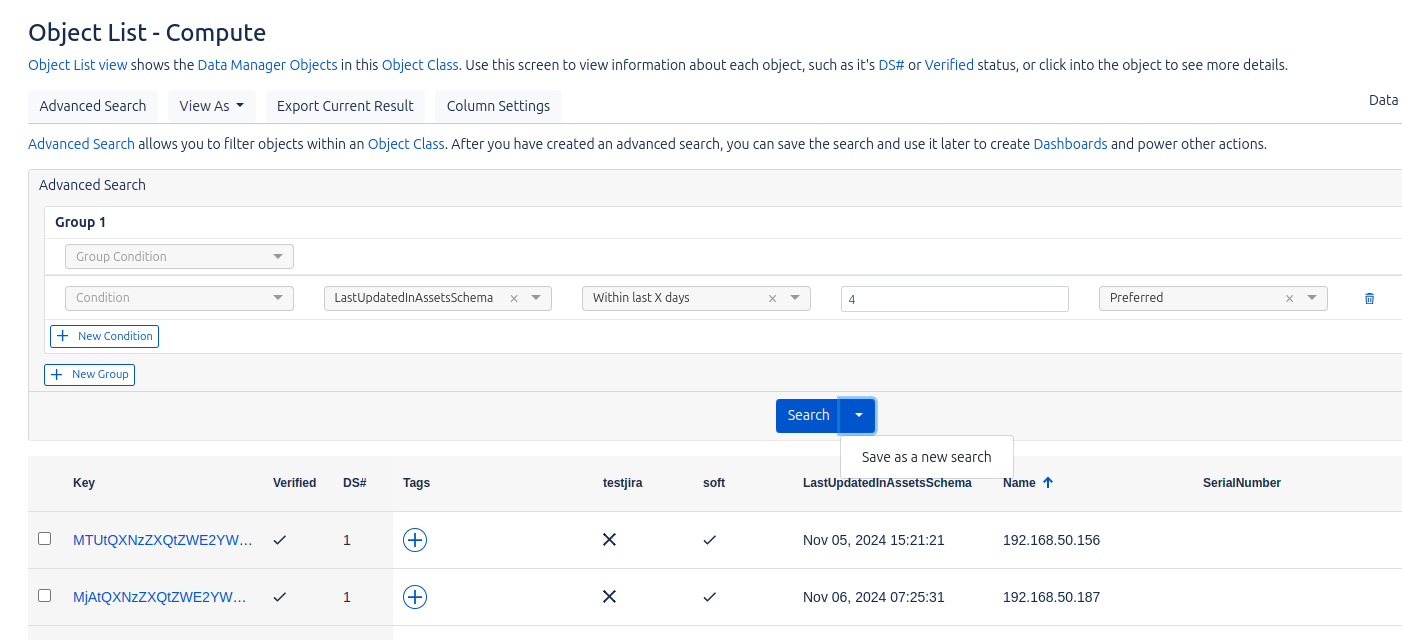
Data Source Staging
Podemos visualizar los datos importados desde la fuente de datos (data source), lo que nos permite revisar la información que ha sido transferida al sistema. Es importante señalar que no se muestran los datos almacenados actualmente en Data Manager, sino solo los que provienen directamente de la fuente externa antes de ser procesados o almacenados en la plataforma.
Analysis
En esta sección, analizaremos y filtraremos los datos que ya han sido limpiados e importados desde las fuentes de datos (datasources) a Data Manager, y que ahora se encuentran almacenados en los object class correspondientes. Esta organización de los datos está definida por Data Manager y permite estructurarlos según su tipo.
Los principales tipos de objetos son:
- Compute: Representa computadoras, dispositivos o servidores.
- Network: Representa redes o dispositivos de red, como enrutadores o firewalls.
- People: Representa usuarios.
- Software: Representa productos de software.
- Peripherals: Representa hardware periférico, como impresoras o ratones.
Al hacer clic en cada object class, podremos ver los datos almacenados en cada uno de ellos. Además, tendremos la opción de ejecutar consultas sobre estos datos y guardarlas para su posterior uso en los dashboards, lo que facilita el análisis y la visualización de la información.
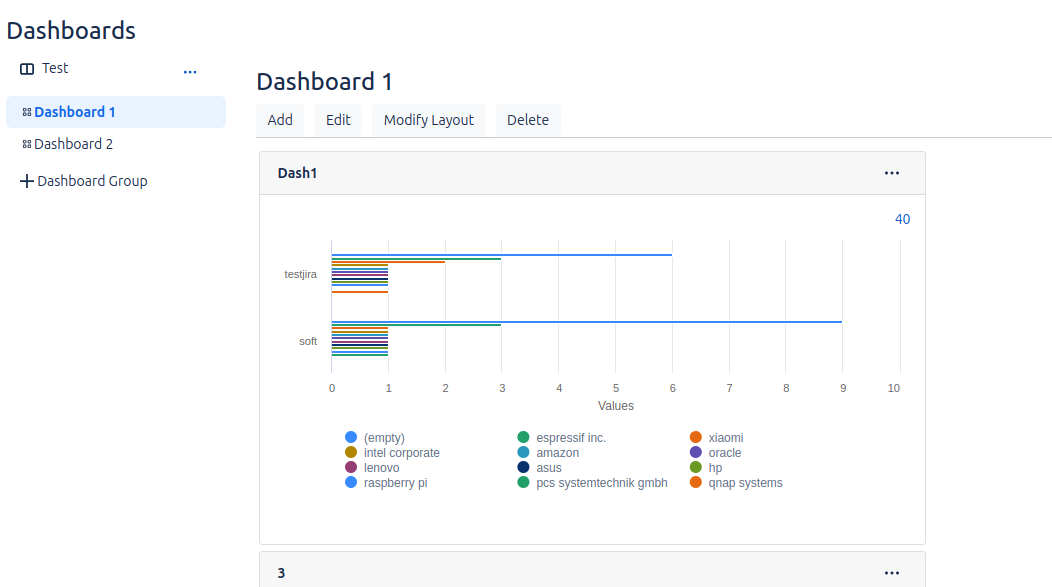
Dashboards
Podremos representar los datos almacenados en Analysis mediante gráficas, aprovechando los filtros previamente aplicados en ese apartado.
Downloads
Actualmente, Data Manager aún no se integra de forma automática con Assets. Mientras esta opción esté en desarrollo, la herramienta ofrece la posibilidad de exportar e importar datos en Assets mediante el uso de archivos CSV.
Para realizar una exportación, en el apartado anterior de Analitycs, podemos realizar búsquedas personalizadas. Desde esa misma pantalla, tenemos la opción de solicitar la exportación de los datos. Durante este proceso, se nos pedirá que proporcionemos un nombre para identificar el trabajo de exportación, facilitando su gestión y seguimiento.
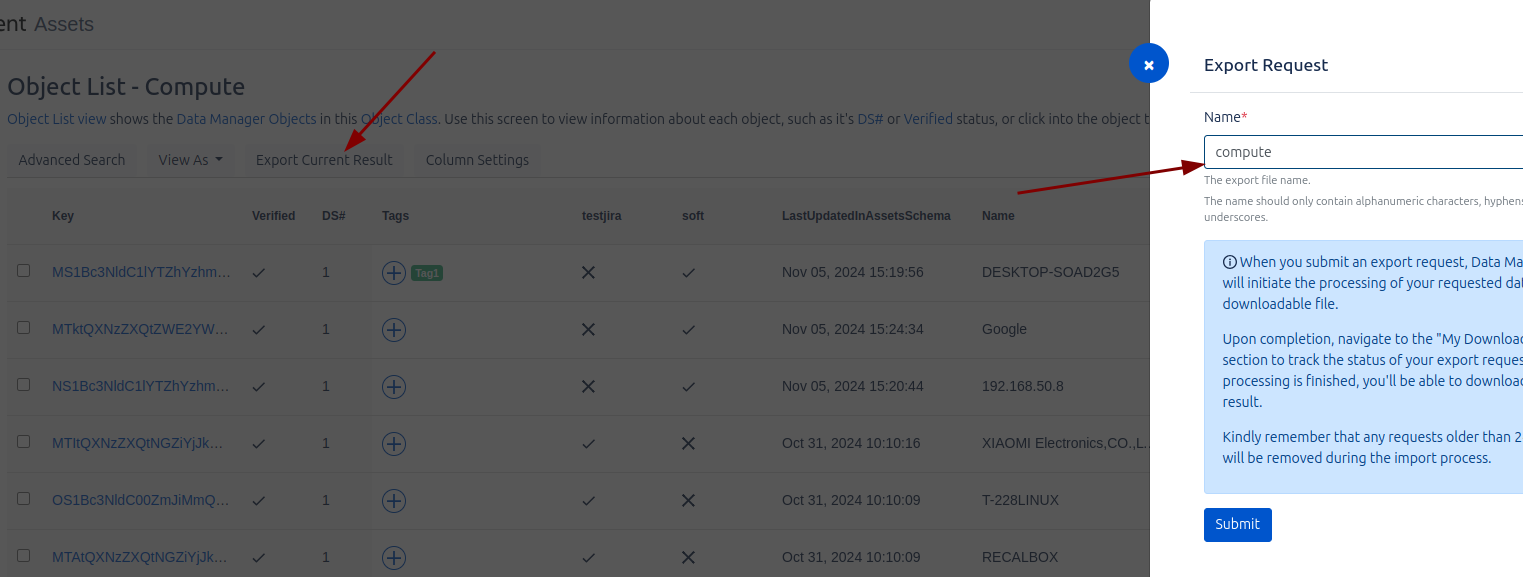
Una vez realizada la exportación, podremos ir a la sección de Downloads para descargar el archivo CSV generado y importarlo en Assets.

Seguramente ya te habrás dado cuenta… pero esta funcionalidad solo está disponible en las versiones Premium y Enterprise de Jira Service Management, las únicas en las que por ahora podemos disfrutar de Assets. Recuerda que, si necesitas ayuda para gestionar tus licencias, podemos ayudarte 😉